ServiceWorker作为前端革命领袖,毫不夸张地被誉为前端黑科技,此文将阐述如何巧妙的使用它来实现一些看起来匪夷所思的事情。
Warning
此文为最基本的SW使用基础,如果你只是想来白嫖代码的建议退出选择下一篇实操文章.
起因 - 巨厦坍塌
2021/12/20日,赶在旧年的末尾,一则JSdelivrSSL证书错误缓缓上了v2ex论坛热点。
此前JSD由于各种原因,曾经不正常了一段时间,所以大家并未对此感冒.正当人们以为这只是JSdelivr每年一度的年经阵痛,发个issue,过一段时间就好了的时候.官方直接爆出大料:JSDelivr had lost their ICP license
由此可见,过去的几年里,当人们发现JSD对个人面向国内加速拥有者无与伦比的效果时,各种滥用方式层出不穷:图床曾一阵流行,国内搜索引擎JSdelivr十有八九都是作为图床的,连PicGo插件都出了Github+JSdelivr图床;猛一点的,直接做视频床,甚至为了突破单文件20M限制开发了一套ts切片m3u8一条龙服务;作妖的,托管了不少突破网络审查的脚本和规则集;寻死的,添加了大量的政治宗教敏感,有些甚至不配称为宗教,直接上来就是骗钱的.
jsd并不是没有发布许可条款,但这并不能阻止白嫖大军的进程。在羊毛大军中,只要是你是免费的、公益的,你就要做好被薅爆的结果。但是薅羊毛的前提是羊还活着,倘若羊被薅死了,哪来的羊毛给诸君所薅?
总之,不管怎样,JSDelivr在决定将节点设置为NearChina,可以肯定的是,在最近很长一段时间内,我们都无法享受国内外双料同时加速的快感,换句话说,jsd在中国就被永久地打入了冷宫。
视线转向国内,jsd的替代品并不少。早在我写图床的千层套路我就试着假想jsd不可用时,我们该用什么。最终我给出的一份较为完美的答案-npm图床,优点无非就是镜像多速度快,许可条款较为宽松,缺点也很明显,需要安装node,用专门的客户端上传。
那事情就逐渐变得扑朔迷离起来了,我们应当如何选择合理的CDN加速器呢。
这时候,我想起了前端黑科技Serviceworker。是的,这种情况下使用SW最为巧妙不过,它可以在后台自动优选最佳的CDN,甚至可以用黑中黑Promise.any打出一套漂亮的并行拳。经过两天的完善,我终于写出了一套具有离线可达、绕备、优选CDN、跟踪统计合一的SW脚本。此博客使用的SW
接下来我将从头开始讲述ServiceWorker的妙用。
Before Start
What Is The ServiceWorker
网上对于SW的解释比较模糊,在这里,我将其定义为用户浏览器里的服务器,功能强大到令人发指。是的,接下来的两张图你应该能显著的看到这一差距:
在第一张图中,用户和服务器的关系直的就像电线杆,用户想要什么,服务器就还给他什么。
第二张图中,用户在被ServiceWorker控制的页面中,无论向哪个服务器发起请求,其过程都会被SW捕获,SW可以仿佛不存在一般单纯地请求服务器,返回原本应该返回的内容【透明代理】;也可以对当前服务器返回的内容进行随意的捏造、修改【请求修改结果】;甚至可以将请求指向完全另一台服务器,返回不是此服务器应该返回的内容【移花接木】;当然,SW也可以直接返回已经存储在本地的文件,甚至离线的时候也能返回【离线访问可达性】。
由于SW对于用户页面的操纵实在过于强大,因此,它被设计成不可跨域请求、SW脚本必须在同一域名下、必须在HTTPS条件下运行、不可操纵DOM和BOM,同样的,为了避免阻塞和延迟,SW也被特意设计成完全异步的。这些点将会在后面一一讲述。
当然,开发者至上,为了方便本地调试,本机地址
localhost和127.0.0.1被浏览器所信任,允许以非HTTPS方式运行serviceworker。
What Relationship Between ServiceWorker and PWA
很多人看到sw,第一反应是PWA,即渐进式Web应用。实际上,SW确实是PWA的核心与灵魂,但SW在PWA中起的主要作用是缓存文件,提供给离线访问。并没有完整地发挥出SW的巧妙用法。
SW可以完全脱离PWA存在,当然,PWA可离不开SW :)
And WorkBox ?
WorkBox是谷歌开发的一款基于SW的缓存控制器,其主要目的是方便维护PWA。核心依旧是SW,但还是没有SW原本的自定义程度高(
Why Not WorkBox ?
首先,博客呢,是没有必要用PWA,有SW做中间件足矣。同时,WorkBox只能简单的缓存数据,并不能做到拦截篡改请求的功能,尤其不能精准把握每一个资源的缓存情况,自定义程度并不高。
自己编写SW,格局就打开了
Start From Zero
安装 / Install
首先,SW的本质是JS脚本,要安装它必须要经过一个html。毕竟,只有拿到了html,JS才能运行于DOM上下文。
剥离层层加成,安装的代码只有一行
1 | navigator.serviceWorker.register('/sw.js') |
其中,/sw.js即为ServiceWorker脚本所在,由于安全性,你不能加载跨域的SW。
例如,当前网页为https://blog.cyfan.top,以下加载位置是允许的
1 | /sw.js |
以下加载是不允许的:
1 | http://blog.cyfan.top/sw.js#非HTTPS |
在加载前,我们最好判断一下dom是否加载完了,不然安装sw可能会卡dom
加载完成后,register函数将返回一个Promise,由于前端大多不适用于异步,我们通常以同步的方式.then()和.catch()来获取是否加载成功。
为了方便判断脚本是否能够加载,我们还要判断navigator里有无sw这一属性'serviceWorker' in navigator。
由于SW安装后,页面需要刷新后才能交给SW所宰割,同时为了避免浏览器缓存的影响,我通常采用修改search的方式强刷新,而不是通过reload函数。同样的,为了避免刚安装完就刷新的尴尬感,建议用setTimeout延迟一秒刷新。
简易的完整安装代码如下:
1 | <script> |
一刷新,世界就变成了ServiceWorker的瓮中之鳖,接下来,该是SW脚本正式登场的时候了。
SW安装初始化 / Installations
首先,先尴尬的开一个空缓存列表:
1 | const CACHE_NAME = 'ICDNCache';//可以为Cache版本号,但这样可能会导致缓存冗余累积 |
cachelist里面填写的是预缓存网址,例如在离线时返回的错误页面。此处不宜添加过多网址,此处点名@一下Akilar。
此处我建议只缓存离线页面展示的内容:
1 | let cachelist = [ |
同时监听sw安装时开启此缓存空间:
1 | self.addEventListener('install', async function (installEvent) { |
由于SW完全没有办法访问DOM,因此对于全局变量,不应当用window,而是self指代自己。
addEventListener这一监听器将监听install,也就是这一段代码只会在脚本首次安装和更新时运行.
skipWaiting的作用是促进新版本sw跳过waiting这一阶段,直接active。
关于SW的状态(waiting,installing,activing)将在文后详细解释。
installEvent.waitUntil的作用是直接结束安装过程的等待,待会在后台完成开启缓存空间这一操作。
cache.addAll将会直接获取cachelist里面所有的网址并直接缓存到CacheStorage。如果此处网址过多,将在页面加载时疯狂请求所有的url~~(例如1k个)~~
现在,SW初始化已经完成了。接下来,我将讲述SW如何捕获页面的请求。
捕获请求 / Fetch Event
添加监听器 / AddEventListener
1 | self.addEventListener('fetch', async event => { |
第一行很简单,绑定一个监听器,监听fetch事件,即网页向服务器获取请求,也就是相当于前端的XMLHTTPRequest
event.respondWith即设定返回内容,交给handle主函数处理,传参event.request。这是一个Request对象,里面包含了请求的详细信息。
接下来,我们开始实战吧。
以下所有内容均针对handle修改
透明代理 / Transparent Proxy
顾名思义,此实战脚本的作用是SW代理目前的所有流量但不进行修改,仿佛SW不存在一般。
1 | const handle = async(req)=>{ |
fetch这个函数相当于前端的ajax或者XMLHTTPRequest,作用是发起一个请求,获得一个返回值。由于sw不可访问window,在sw中是无法使用ajax或XMLHTTPRequest。同时,fetch是一个异步函数,直接调用它会返回一个Promise。
fetch只能传递Requset对象,而Requset对象有两个参数(url,[option]),第一个参数是网址,第二个参数为Request的内容,例如body或header。
此脚本适用于卸载ServiceWorker的替换脚本。因为sw在无法拉取新版本时不会主动卸载,依旧保持运行,填入一个透明代理sw即可。
由于SW冷启动【即页面关闭后SW】处于暂停状态是从硬盘读取的,这会导致第一次请求有少许性能延迟[~10ms]。
篡改请求 / Edit Requset
对于一张图片,有时候服务端会变态到让你必须用POST协议才能获得,此时用SW篡改最为方便。
1 | const handle = async (req) => { |
注意,在ServiceWorker里面,header头是不能修改refferer和origin的,因此此方法无法绕开新浪图床反盗链
篡改响应 / Edit Response
这个例子会检测返回内容,若为html,将把所有的"TEST"都替换成"SHIT"
1 | const handle = async (req) => { |
const resp = res.clone()由于Response的body一旦被读取,这个body就会被锁死,再也无法读取。clone()能够创造出响应的副本用于处理。
resp.headers.get('content-type')通过读取响应的头,判断是否包含text/html,如果是,将响应以text()异步流的方式读取,然后正则替换掉响应内容,并还原头和响应Code。
返回的内容必须是Response对象,所以new Response构建一个新对象,并直接返回。不匹配html头将直接原封不动地透明代理。
移花接木 / Graft Request To Another Server
unpkg.zhimg.com是unpkg.com的镜像网站。此脚本将会把所有的unpkg.com流量直接拦截到unpkg.zhimg.com,用于中国大陆内CDN加速。
由于npm镜像固定为GET请求方式并且没有其他鉴权需求,所以我们没有必要还原Request其他数据。
1 | const handle = async (req) => { |
domain.match捕获请求中是否有待替换域名,检查出来后直接replace掉域名,如果没有匹配到,直接透明代理走掉。
并行请求 / Request Parallelly
SW中又一大黑科技隆重登场=>Promise.any,这个函数拥有另外两个衍生兄弟Promise.all&Promise.race。下面我将简单介绍这三种方式
Promose.all
当列表中所有的Promise都resolve[即成功]后,这个函数才会返回resolve,只要有一个返回reject,整个函数都会reject。
1 | Promise.all([ |
这个函数将会请求三个网址,当每一个网址都链接联通后,整个函数将会返回一个列表:
1 | [Response1,Response2,Response3] |
当任何一个fetch失败[即reject]后,整个Promise.all函数都会直接reject并报错。
此函数可以检测网络连通性,由于采取并行处理,相比以前的循环效率要高不少。
这是一段检测国内国外网络连通性的测试。
没有采用Promise.all的代码和效果:
1 | const test = async () => { |
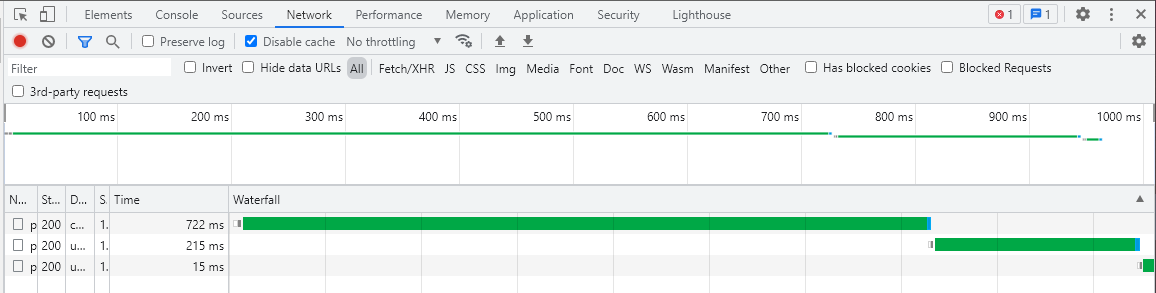
采用循环,await会堵塞循环,直到这次请求完成后才能执行下一个。如果有任何一个url长时间无法联通,将会导致极长的检测时间浪费。
1 |
|

Promise.all几乎在一瞬间请求所有的url,其请求时并行,每一个请求并不会堵塞其他请求,函数总耗时为最长请求耗时。
Promise.race
此函数也是并行执行,不过与all不同的是,只要有任何一个函数完成,就立刻返回,无论其是否reject或者resolve。
这个函数比较适合用于同时请求一些不关心结果,只要访问达到了即可,例如统计、签到等应用场景。
Promise.any
这个函数非常的有用,其作用和race接近,不过与之不同的是,any会同时检测结果是否resolve。其并行处理后,只要有任何一个返回正确,就直接返回哪个最快的请求结果,返回错误的直接忽视,除非所有的请求都失败了,才会返回reject
这是一段同时请求jquery的package.json代码,它将从四个镜像同时请求:
1 | const get_json = () => { |
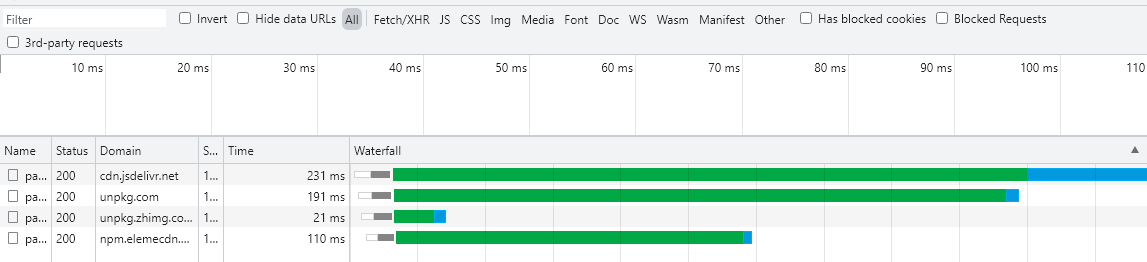
函数将会在21ms上下返回json中的数据。
此函数的好处在于可以在用户客户端判断哪一个镜像发挥速度最快,并保证用户每一次获取都能达到最大速度。同时,任何一个镜像站崩溃了都不会造成太大的影响,脚本将自动从其他源拉取信息。
除非所有源都炸了,否则此请求不会失败。
但是,我们会额外地发现,当知乎镜像返回最新版本后,其余的请求依旧在继续,只是没有被利用到而已。
这会堵塞浏览器并发线程数,并且会造成额外的流量浪费。所以我们应该在其中任何一个请求完成后就打断其余请求。
fetch有一个abort对象,只要刚开始new AbortController()指定控制器,在init的里面指定控制器的signal即可将其标记为待打断函数,最后controller.abort()即可打断。
那么,很多同学就会开始这么写了:
1 | const get_json = () => { |
但很快,你就会发现它报错了:Uncaught DOMException: The user aborted a request.,并且没有任何数据输出。
让我们看一下Network选项卡:

其中,知乎返回的最快,但他并没有完整的返回文件[源文件1.8KB,但他只返回了1.4KB]。这也直接导致了整个函数的fail。
原因出在fetch上,这个函数在获得响应之后就立刻resolve了Response,但这个时候body并没有下载完成,即fetch的返回基于状态的而非基于响应内容,当其中fetch已经拿到了完整的状态代码,它就立刻把Response丢给了下一个管道函数,而此时status正确,abort打断了包括这一个fetch的所有请求,fetch就直接工作不正常。
我个人采取的方式是读取arrayBuffer,阻塞fetch函数直到把整个文件下载下来。函数名为PauseProgress
1 | const get_json = () => { |

在这其中通过arrayBuffer()方法异步读取res的body,将其读取为二进制文件,并新建一个新的Response,还原状态和头,然后丢给管道函数同步处理。
在这里,我们就实现了暴力并发,以流量换速度的方式。同时也获得了一个高可用的SW负载均衡器。
这一段函数可以这样写在SW中:
1 | //... |
另外,Promise.any,兼容性比较差:

因此,我的解决办法是判断浏览器如果不支持,就提前polyfill一下:
1 | if (!Promise.any) { |
缓存控制 / Cache
持久化缓存 / Cache Persistently
对于来自CDN的流量,大部分是持久不变的,因此,如果我们将文件获得后直接填入缓存,之后访问也直接从本地缓存中读取,那将大大提升访问速度。
1 | const handle = async (req) => { |
cache_url_list列出所有待匹配的域名(包括http/https头是为了避免误杀其他url),然后for开始遍历待列表,如果url中匹配到了,开始执行返回缓存操作。
cache是一个近似于Key/Value(键名/键值),只要有对应的Request(KEY),就能匹配到响应的Response(VALUE)。
caches.match(req)将会试图在CacheStorage中匹配请求的url获取值,然后丢给管道同步函数then,传参resp为Cache匹配到的值。
此时管道内将尝试返回resp,如果resp为null或undefined[即获取不到对应的缓存],将执行fetch操作,fetch成功后将open打开CacheStorage,并put放入缓存。此时如果fetch失败将直接报错,不写入缓存。
在下一次获取同一个URL的时候,缓存匹配到的将不再是空白值,此时fetch不执行,直接返回缓存,大大提升了速度。
由于npm的cdn对于latest缓存并不是持久有效的,所以我们最好还是判断一下url版本中是否以@latest为结尾。
1 | const is_latest = (url) => { |
离线化缓存 / Cache For Offline
对于博客来说,并不是所有内容都是一成不变的。传统PWA采用SW更新同时刷新缓存,这样不够灵活,同时刷新缓存的版本号管理也存在着很大的漏洞,长时间访问极易造成庞大的缓存冗余。因此,对于博客的缓存,我们要保证用户每次获取都是最新的版本,但也要保证用户在离线时能看到最后一个版本的内容。
因此,针对博客来说,策略应该是先获取最新内容,然后更新本地缓存,最后返回最新内容;离线的时候,尝试访问最新内容会回退到缓存,如果缓存也没有,就回退到错误页面。
即:
1 | Online: |
1 | const handle = async (req) => { |
if (!res) { throw 'error' } 如果没有返回值,直接抛出错误,会被下面的Catch捕获,返回缓存或错误页面
return resp || caches.match(new Request('/offline.html')) 返回缓存获得的内容。如果没有,就返回从缓存中拿到的错误网页。此处offline.html应该在最开始的时候就缓存好
持久化存储 / Storage Persistently
由于sw中无window,我们不能使用localStorage和sessionStorage。SW脚本会在所有页面都关闭或重载的时候丢失原先的数据。因此,如果想要使用持久化存储,我们只能使用CacheAPI和IndexdDB。
IndexdDB
这货结构表类型类似于SQL,能够存储JSON对象和数据内容,但版本更新及其操作非常麻烦,因此本文不对此做过多解释。
CacheAPI
这东西原本是用来缓存响应,但其本身的特性我们可以将其改造成一个简易的Key/Value数据表,可以存储文本/二进制,可扩展性远远比IndexdDB要好。
1 | self.CACHE_NAME = 'SWHelperCache'; |
使用操作:
写入key,value:
1 | await db.wtite(key,value) |
以文本方式读取key:
1 | await db.read(key) |
以二进制方式读取key:
1 | await db.read_arrayBuffer(key) |
其余的blob读取、delete操作此处不过多阐述。
页面与SW通信 / Build Communication with Page and ServiceWorker
单向连接 / Unidirectional Connect
Clients To SW
浏览器 => SW
ServiceWorker中有一个非常简单的APIpostMessage,全路径为navigator.serviceWorker.controller.postMessage.
因此,如果你只是作为页面单方面传递给SW,此api是个不错的选择.
前端写法
1 | const data = 123 |
SW接收
1 | self.addEventListener('message', (event) => { |
此方法可用于单方面向SW提交数据,但无需返回值.比如提示SW可以SkipWaiting,或者提交前端统计数据等等.
SW To Clients
首先,Clients必须要从SW中的一个event事件中获取,比如fetch.无法从message事件中获取client.
1 | addEventListener('fetch', event => { |
双向通讯 / Connect Each
浏览器 <=> SW
我们拥有两种方式双向通讯:
- Broadcast Channel API 多对多,广播形式.
- Message Channel 一对一
MessageChannel
顾名思义,MessageChannel API 设置了一个可以发送消息的通道。
该实现可以归结为3个步骤。
1.在两侧设置事件侦听器以接收message 事件
2.通过发送port并将其存储在SW中,建立与SW的连接。
3.使用存储的port回复客户端
前端写法
1 | const messageChannel = new MessageChannel(); |
SW端写法
1 | self.addEventListener("message", event => { |
然后查看控制台,你就会看到里面一直在乒乒乓乓,说明成功了.
我们简单的改写一下,变成异步形式传输数据:
1 | const mCh = { |
由于MessageChannel特性,一个port只要不是连续传输数据就会被断开.所以每次传输时我们要先初始化,后发送数据.
由于传输时无状态的,我们将每一个包都打上特定的uuid,返回包里也写上对应的uuid即可判断那个包是哪个对应的返回值.
SW端也要做一点点相应的改动
1 | self.ClientPort.postMessage({ |
这样,一个兼容性较好的SW双向传输就解决了.
Broadcast Channel
请注意,BroadCast虽然写法建议,但是对浏览器兼容性要求非常高[Chrome 54,IOS Safari全线不支持].用此api请三思.
另外,由于是广播形式,一个页面如果有多个SW,他们会同时收到消息.
前端
1 | const broadcast = new BroadcastChannel('Channel Name'); |
SW端
1 | const broadcast = new BroadcastChannel('Channel Name'); |
只要ChannelName对应,即可在里面顺利传输消息.
细节与注意 / Something Small But Need to Be Mentioned
无法修改的 Header
由于ServiceWorker本质上仍然属于浏览器,因此,你无法控制例如header中的Host\Refferer\Access-Control-Allow-Origin用于绕过防盗链\CORS\指定host选择ip
难以卸载的 SW
SW一大特性,一旦被安装,就不能通过传统方式卸载掉.
如果你直接删除sw.js文件并删除安装代码,那么,新用户是不会被安装的,但是原先已经安装过的用户sw会继续劫持这他们的网页,导致老用户网页不更新或者出现异常.
正确的删除方法是将安装代码改成卸载代码:
1 | navigator.serviceWorker.getRegistrations().then(function(registrations) { |
并将sw内容改成透明代理,方便没有卸载的用户正常使用.
堵塞整个浏览器的代码
由于SW运行在DOM上下文,如果在sw中执行一些消耗资源的代码会直接耗尽浏览器资源,与dom不同的是,dom耗资源代码只会堵塞一个线程,另一个线程依旧可以正常工作,而sw一旦堵塞会将整个浏览器堵死.因此sw固然可以更快的计算,但万不可将一些极易死机的代码交给sw处理.
End
这篇文章结尾的很仓促,毕竟已经快拖了一个月了,也有很多东西没有讲清楚,未来可能会小修小改.
篇幅所限,一些sw其他功能并没有详细讲述,比如后台更新或者推送通知.这些功能在实际开发中并不是特别有用,或者在国内大环境下并不适合.可能这些功能会在下一篇文章,sw的实操中讲述.
停下笔的时候,hexo统计这篇文章已经将近1万字,阅读时间近100分钟.不过我认为这值得,毕竟sw就是这么一个凭借着奇思妙想就能绽放出Spark的事物.唯有独特的创造力才能激发无限可能.
当然,这篇文章讲述的都是些非常基础的东西,那在下一篇文章,我会贴出一个个demo,希望你们能对这些充满着智慧的样例激发你们的灵感.
另外,在祝贺你们,虎年大吉,新年快乐!
关于本文
由 CyanFalse 撰写, 采用 CC BY-NC 4.0 许可协议.
Wait...